Classification Trees
Summary
A classification tree is a type of Decision Tree that segregates data into different categories.
Building Data into a Classification Tree
The Issue
The issue with turning data into a classification tree is how to evaluate which different features you should start with in order to categorise your data correctly. In other words, which question should be asked in which order in the classification tree.
Example
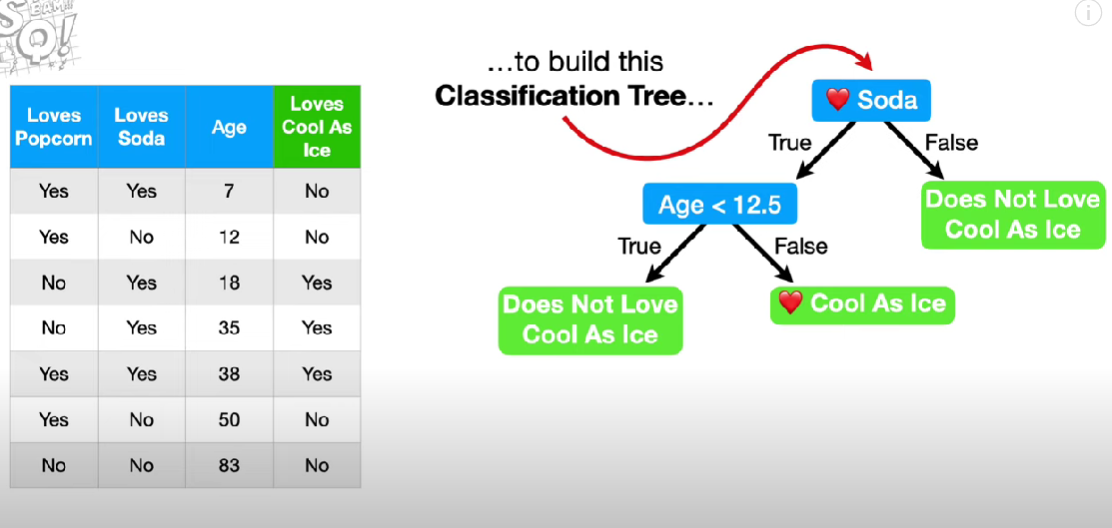
Below is an example of a decision tree built from data. We will now work backwards using statistical methods to decide in which order the questions should be asked to create the classification tree. For this we use Gini Impurity.
Gini Impurity
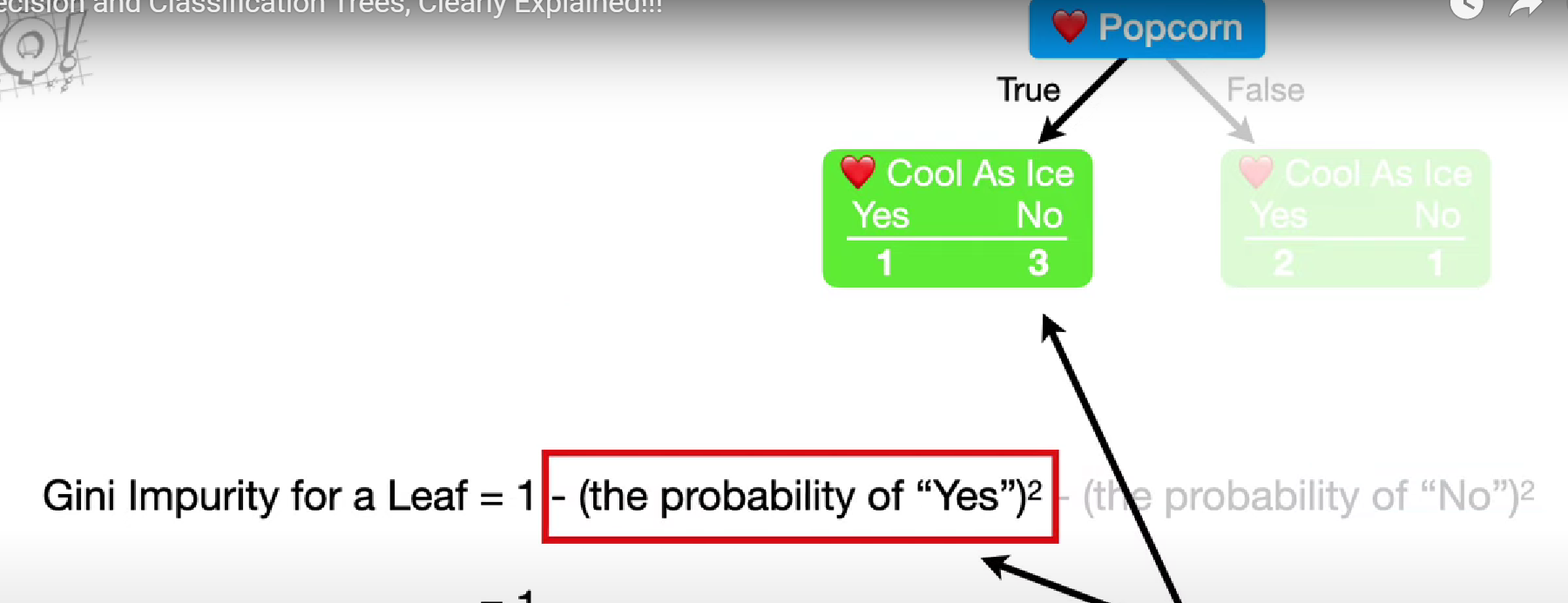
Gini Impurity is a statistical method used to quantify the purity of a feature in predicting a specific class. Therefore you would use the feature with the lowest Gini Impurity as the Root Node.
Terminology
Purity
In a decision tree, purity refers to how much a group of data points at a node belong to the same class. A node is considered pure if all the data points in it are of the same class. The more mixed the classes are in a node, the less pure it is. Decision trees aim to create nodes that are as pure as possible, meaning each node ideally contains data points from just one class.