Random Forests
Summary
Random forest is a commonly-used machine learning algorithm, trademarked by Leo Breiman and Adele Cutler, that combines the output of multiple decision trees to reach a single result
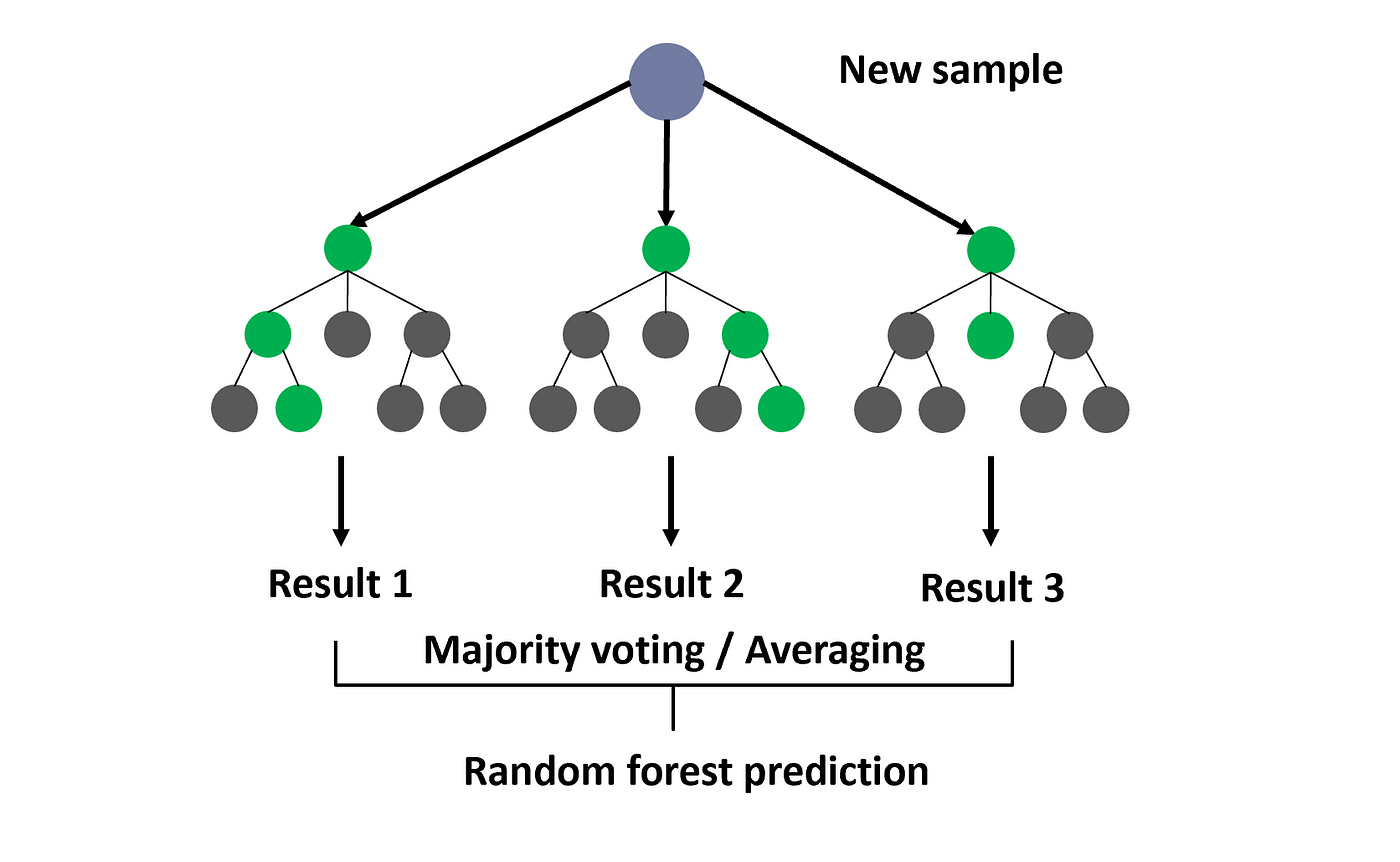
In summary, a random forest uses a single dataset to create multiple Decision Trees to predict a certain value. These decision trees are randomly generated and when a new value needs to be predicted, it is run down each of the multiple decision trees created and the majority vote of all the decision trees will be the predicted value.
Related Sections
Creation of a Random Forest
1Bootstrapping your dataset
The creation of a random forest starts with creating a bootstrapped dataset from your original dataset. Bootstrapping refers to creating a new population from your original dataset. This involves randomly selecting rows in the original dataset, allowing duplicates, to create a new dataset. This is also referred to as bagging.
2Creating your decision trees
From your dataset, you will now need to create your Decision Trees. Unlike the normal procedures in creating your decision trees, we will limit the number of features available for evaluation at each node.
This would mean we would only be selecting from a random subset of the features at each node and choosing from this smaller population which feature is the best suited.
The reason behind this is to create as many diverse decision trees as possible and not favour any specific features in the original dataset. This solves the problem of Overfitting.Learn more about Bias vs Variance
3Rinse and Repeat
We repeat the above process 100's or 1000's of times until we have a 'forest' of decision trees. We then use these decision trees to predict a new piece of data. We run the new data down all decision trees and use either a majority vote or average result (for regression problems) as the overall answer to our prediction.